В части 5.1 подготовили домашний сервер в качестве бэкенда для связки vps-as-edge. Сейчас он умеет хостить сервисы, ограничен только вашим железом, но не виден снаружи - он за NAT провайдера.
Статья прикладная. В финале - работающая mesh-сеть между VPS, домашним сервером и остальными устройствами, с мониторингом и алертами на координатор. Если после раздела “Кратко о механике headscale” что-то осталось неочевидным, советую один из двух вариантов - или разбираться по ходу чтения статьи, или сначала подтянуть знания о сетях, потому что объяснение с нуля, как работает headscale под капотом, заняло бы несколько тысяч строк. Для чтения этой статьи нужно понимать, что было в предыдущих.
В конфигах и выводах команд встретится hostname моего домашнего сервера - mio. У вас он будет свой - не копируйте команды бездумно.
Содержание:
- Главное
- Финальный чеклист
- Кратко о механике headscale
-
- DNS-запись для поддомена
-
- Каталоги и
config.yaml
- Каталоги и
-
docker-compose.yml
-
- Caddy-блок для
headscale.insomnia.cat
- Caddy-блок для
-
- Запуск и проверка
/health
- Запуск и проверка
-
- Пользователь и preauth-ключ
- Переименование пользователя и ноды
-
- Минимальный тест работоспособности - регистрация одной ноды
-
- Нативные метрики headscale в Prometheus
- Дашборд под нативные метрики
-
- Метрики нод через tailscale-exporter
- 9.1. Включить gRPC в headscale без TLS
- 9.2. API-ключ для exporter
- 9.3. Ключ в
.env-файл рядом с compose - 9.4. Сервис в
docker-compose.yml - 9.5. Поднимаем headscale и exporter
- 9.6. Job в Prometheus
- 9.7. Импорт дашборда
-
- Подключение домашнего сервера к tailnet
- Установка Tailscale на домашнем сервере (Debian 13)
- Регистрация ноды на координаторе
- Проверка регистрации
-
- Tailscale-клиент на самом VPS
-
- Метрики домашнего сервера через tailnet (node_exporter + cAdvisor)
- 12.1. node_exporter на домашнем сервере
- 12.2. Firewall
- 12.3. Добавить target в Prometheus на VPS
- 12.4. cAdvisor на домашнем сервере
-
- Минимальные алерты на headscale
- 13.1. Координатор недоступен
- 13.2. Экспортер не достучался до headscale
- Проверка
- Что дальше
Главное
- Координатор - за Caddy, на отдельном поддомене. Tailscale-клиенты требуют HTTPS на 443, headscale внутри контейнера слушает чистый HTTP. Caddy терминирует TLS и проксирует на loopback.
- Порт метрик (9090) на хост не пробрасываем вообще. Контейнер подключаем к внешней docker-сети
observability_default, и Prometheus стучится к нему по имени контейнераheadscale:9090(резолвится встроенным docker-DNS). На хосте и снаружи метрики не светятся. - Версия образа фиксированная, не
latest. - Алерт на координатор крайне желателен. Без него при падении headscale становится недоступна регистрация новых нод.
Финальный чеклист
-
DNS A-запись
headscale.insomnia.cat-> IP_VPS -
~/services/headscale/{config,lib}созданы, владелецinsomnia -
config/config.yamlскачан под тегv0.28.0и отредактирован:server_url,listen_addr: 0.0.0.0:8080,metrics_listen_addr: 0.0.0.0:9090,grpc_listen_addr: 0.0.0.0:50443,grpc_allow_insecure: true,noise.private_key_path,database.sqlite.path,derp.server.enabled: false,derp.urls,dns.magic_dns: true,dns.base_domain: insomnia.internal,dns.nameservers.global,log.level -
caddy validateпроходит, блокheadscale.insomnia.catзагружен,systemctl restart caddyбез ошибок (reloadне работает -admin offиз части 3) -
curl -sS https://headscale.insomnia.cat/healthотвечает{"status":"pass"} -
Создан пользователь
insomniaи выпущен preauth-ключ -
Тест: с любого Tailscale-клиента нода регистрируется и видна в
headscale nodes list -
Контейнер
headscaleподключен к docker-сетиobservability_default -
В Prometheus job
headscaleв состоянииup - Импортирован дашборд для нативных метрик headscale (gist)
-
headscale apikeys createвыпущен, ключ лежит в~/services/headscale/.env(chmod 600) -
tailscale-exporterподнят, в Prometheus jobtailscale-exporterвup,headscale_scrape_collector_success == 1 -
Импортирован дашборд
Headscale Overview(Grafana ID 24516), панели показывают данные -
Домашний сервер в tailnet:
tailscale statusпоказывает100.64.x.x -
VPS в tailnet:
tailscale statusс домашнего сервера видит VPS - С VPS пингуется домашний сервер и наоборот
-
В Prometheus job
nodeдобавлен targetmio.insomnia.internal:9100. Оба инстанса -vpsиmio- вup -
На домашнем сервере поднят cAdvisor; в Prometheus job
cadvisorвторой target вup(раздел 12.4) -
Алерт
Headscale coordinator downсоздан в Grafana и сработал на проверочномdocker compose -f ~/services/headscale/docker-compose.yml stop headscale -
Алерт
tailscale-exporter not collectingсоздан в Grafana
Кратко о механике headscale
Tailscale - это VPN-сервис, работающий как mesh-сеть, то есть имеющий топологию, при которой все узлы между собой равнозначны (в отличие от клиент-серверной архитектуры). Он бесплатный для малого количества устройств, и вполне можно было бы взять и его, но tailscale записывает метаинформацию об узлах, которые вы используете (сам трафик данных он не видит). Мне это не нравится, и было интересно поднять свой, поэтому я выбрал headscale.
Headscale - open source реализация координатора tailscale. Связка “VPS-координатор + ноды дома” - один из самых популярных сценариев self-hosted, поэтому берем именно его. Из альтернатив есть Innernet и NetBird, но дальше пишу только про headscale.
Выше я написал, что сеть имеет mesh-топологию. Если точнее, headscale разбивается на два слоя:
- Control plane - управляющий слой. Имеет централизованный координатор, который помогает узлам в сети находить друг друга, обмениваться ключами, управлять правами доступа, резолвить DNS и так далее.
- Data plane - слой обмена данными. Здесь настоящая децентрализация - если в сеть объединены телефон и домашний ноутбук, то для их связи не нужно ходить через сервер. Под капотом используется WireGuard.
Control plane и data plane независимы, и реальный трафик через координатор не проходит. Если координатор упадет или будет взломан, канал между нодами останется живым и безопасным.
Для клиентов используется официальная реализация tailscale: https://tailscale.com/download. При подключении указываем свой координатор вместо дефолтного. Клиенты есть на все основные платформы. На каждой ноде клиент генерирует пару ключей и держит канал к координатору через созданный для этого сетевой интерфейс.
У headscale для data plane есть три режима соединения. Direct connection - напрямую между устройствами, peer-to-peer WireGuard. DERP-relayed connection - через DERP-сервер, если прямое подключение не удалось пробить (например, оба конца за симметричным NAT, который превращает внутреннюю пару адрес/порт в случайную публичную пару). Tailscale Peer Relay connection - через одну из нод tailnet как ретранслятор; в статье не рассматриваем. Полный разбор - в connection types.
DERP (Designated Encrypted Relay for Packets) - публичный fallback-сервер: помогает нодам найти друг друга при первом коннекте и ретранслирует зашифрованный WireGuard-трафик, если прямое соединение не проходит через NAT. Содержимое DERP не видит. При желании можно поднять свой DERP - см. derp-servers.
CGNAT (Carrier-Grade NAT) - диапазон 100.64.0.0/10, зарезервированный для крупных провайдерских NAT. Tailscale/headscale используют его как пул для внутренних адресов нод - этот диапазон гарантированно не пересечется с домашними подсетями (192.168.x, 10.x, 172.16.x).
MagicDNS - локальный DNS-резолвер на каждой ноде, слушающий на 100.100.100.100. tailscale-клиент на уровне ОС настраивает split-dns: запросы к зоне tailnet (<hostname>.<base_domain>) идут в этот резолвер, остальное - на upstream (Cloudflare, Google, что выставили в конфиге координатора). См. magic dns и quad100.
Ноды получают имена вида <hostname>.<base_domain>, где base_domain задаем в конфиге координатора. В этой статье base_domain: insomnia.internal, поэтому ноды резолвятся как vps.insomnia.internal, mio.insomnia.internal и так далее.
Теперь, когда краткий обзор закончен, начнем настройку.
1. DNS-запись для поддомена
Для регистрации новых устройств нужен headscale-поддомен, на который Caddy будет проксировать запросы. Нужен именно домен (не IP), потому что tailscale-клиент общается с координатором только по HTTPS и валидирует сертификат.
У DNS-провайдера добавляем A-запись:
A headscale IP_VPS TTL 300Где IP_VPS - IP вашего VPS.
Проверяем, что запись резолвится:
dig +short headscale.insomnia.catДолжен вернуться IP VPS. Если ничего - подождать минуту.
2. Каталоги и config.yaml
Как и раньше, все docker-сервисы у нас в ~/services/:
mkdir -p ~/services/headscale/{config,lib}
cd ~/services/headscaleconfig/- здесь будетconfig.yaml.lib/- SQLite-база, ключи и другое.
Скачиваем пример конфига под версию, которую укажем в docker-compose.yml. latest не используем для совместимости - обновляем только руками. На момент написания актуальный релиз - v0.28.0.
Берем конфиг под тег v0.28.0. Ссылка ведет отсюда: headscale.net/stable/ref/configuration.
Кладем его в config/config.yaml и правим следующее:
server_url: https://headscale.insomnia.cat
listen_addr: 0.0.0.0:8080
metrics_listen_addr: 0.0.0.0:9090
grpc_listen_addr: 0.0.0.0:50443
grpc_allow_insecure: true
noise:
private_key_path: /var/lib/headscale/noise_private.key
database:
type: sqlite
sqlite:
path: /var/lib/headscale/db.sqlite
derp:
server:
enabled: false
urls:
- https://controlplane.tailscale.com/derpmap/default
dns:
magic_dns: true
base_domain: insomnia.internal
nameservers:
global:
- 1.1.1.1
- 1.0.0.1
- 2606:4700:4700::1111
- 2606:4700:4700::1001
log:
level: infoСекции acme_* и tls_letsencrypt_* оставляем как в дефолте (пустые значения и tls_letsencrypt_listen: ":http") - TLS терминируется на Caddy, headscale внутри контейнера общается по чистому HTTP.
Что важно:
server_urlобязательно должен быть https, сам домен подставляете из раздела 1.listen_addr: 0.0.0.0:8080иmetrics_listen_addr: 0.0.0.0:9090- это адреса внутри контейнера. На хост наружу пробросим только API (127.0.0.1:8081:8080, потому что у меня хостовой 8080 держит cadvisor), а к метрикам Prometheus сходит внутри docker-сети по имени контейнера.base_domain- это внутренний суффикс tailnet для MagicDNS, не реальный DNS-домен. По нему клиенты внутри tailnet резолвят имена нод (<hostname>.<base_domain>), в публичный DNS он не уходит. Регистрировать ничего не нужно. Я используюinsomnia.internal. Подойдет любой суффикс, ноinternalгарантирует отсутствие конфликтов.dns.nameservers.global- это DNS-серверы, которые headscale раздает клиентам сети для обычных (не headscale) запросов. Я взял дефолт - Cloudflare 1.1.1.1/1.0.0.1 + IPv6.- gRPC слушает внутри контейнера на 50443, наружу порт не пробрасываем. Сейчас он не задействован, но понадобится в разделе 9 для экспорта метрик - tailscale-exporter будет стучаться к нему из соседнего контейнера по docker-сети
observability_default.
3. docker-compose.yml
Конфиг взят отсюда: https://headscale.net/stable/setup/install/container/#configure-and-run-headscale
В ~/services/headscale/docker-compose.yml:
services:
headscale:
image: docker.io/headscale/headscale:0.28.0
container_name: headscale
restart: unless-stopped
mem_limit: 256m
read_only: true
tmpfs:
- /var/run/headscale
ports:
- "127.0.0.1:8081:8080"
volumes:
- ./config:/etc/headscale:ro
- ./lib:/var/lib/headscale
command: serve
healthcheck:
test: ["CMD", "headscale", "health"]
interval: 30s
timeout: 5s
retries: 3
networks:
- default
- observability
networks:
observability:
external: true
name: observability_defaultЧто тут нестандартного по сравнению с примером из доки:
127.0.0.1:8081:8080- проброс API на loopback хоста, чтобы наружу его не выставлять. Caddy реверсит сюда. Хостовой 8080 не использую, потому что он уже занят cadvisor.- Проброс порта 9090 для метрик не нужен. Контейнер подключен к двум docker-сетям:
default- своя локальная для самого compose-проекта,observability- внешняя, в которой живет Prometheus. По ней Prometheus резолвит контейнер по имениheadscaleи стучится к нему напрямую на 9090. Поэтому на хост порт метрик нет смысла открывать. name: observability_default- имя реальной сети из предыдущих частей, которую docker-compose создал для observability-стека. Какая у вас - смотрите черезdocker network ls(скорее всего, такая же, если делали как в предыдущих гайдах).mem_limit: 256m- запас на маленький tailnet (десятки нод). Если упрется в лимит, контейнер уйдет вOOMKilledи перезапустится; видно черезdocker stats headscaleиdocker compose ps. На сотнях нод стоит поднять до512m.
4. Caddy-блок для headscale.insomnia.cat
В /etc/caddy/Caddyfile добавляем блок:
headscale.insomnia.cat {
reverse_proxy localhost:8081
}Валидируем и применяем через restart:
sudo caddy validate --config /etc/caddy/Caddyfile
sudo systemctl restart caddy
sudo journalctl -u caddy -fВ journalctl в течение 5-30 секунд должно появиться:
INFO http enabling automatic TLS certificate management {"domains":[..., "headscale.insomnia.cat"]}
INFO tls.obtain obtaining certificate {"identifier":"headscale.insomnia.cat"}
INFO tls.obtain certificate obtained successfully {"identifier":"headscale.insomnia.cat"}Если в логах Caddyfile input is not formatted:
sudo caddy fmt --overwrite /etc/caddy/Caddyfile5. Запуск и проверка /health
Поднимаем стек:
cd ~/services/headscale
docker compose up -d
docker compose ps
docker compose logs -f headscaleВ логах ожидаем:
headscale | 2026-05-10T21:13:46Z INF listening and serving HTTP on: 0.0.0.0:8080
headscale | 2026-05-10T21:13:46Z INF listening and serving debug and metrics on: 0.0.0.0:9090Health через Caddy:
curl -sS https://headscale.insomnia.cat/healthДолжно быть {"status":"pass"}.
6. Пользователь и preauth-ключ
В headscale user - это единица для ACL (политик доступа) и аутентификации. В простых случаях, если не нужно разделение прав доступа, заводить больше одного юзера нет смысла.
Headscale-CLI вызываем через docker exec. Создаем пользователя insomnia и смотрим присвоенный ему ID:
docker exec headscale headscale users create insomnia
docker exec headscale headscale users listusers list печатает таблицу с колонкой ID - это число нам понадобится, скорее всего, это 1.
Headscale позволяет добавлять ноды двумя способами.
- Через preauth-key удобно, когда есть доступ к терминалу на ноде. В этом случае на координаторе один раз выпускаем токен, на ноде передаем
tailscale up --auth-key=.... - Через регистрацию из клиента - удобно для устройств без терминала (телефон, чужой ноут).На ноде в Tailscale-клиенте указываем custom coordination server, клиент показывает свой key, его подтверждаем командой на сервере.
Покажу оба.
Создаем preauth-ключ, с помощью которого будем добавлять ноды:
docker exec headscale headscale preauthkeys create \
--user 1 --reusable --expiration 24hГде 1 - ваш USER ID.
--reusable - чтобы не заводить на каждую ноду свой ключ. Для постоянной эксплуатации лучше выпускать одноразовые: если reusable-ключ утечет, любой получивший его сможет регистрировать новые ноды до истечения срока, а одноразовый умирает после первой регистрации. На время первичной настройки --reusable экономит время, дальше переходим на одноразовые.
preauthkeys create возвращает ключ, который мы будем использовать для добавления нод. Потерять его не страшно, всегда можно выпустить новый или заэкспайрить через preauthkeys expire --id <ID ключа>. Сами ключи лежат в SQLite.
Посмотреть, какие ключи живы и сколько раз использовались:
docker exec headscale headscale preauthkeys listID | Key/Prefix | Reusable | Ephemeral | Used | Expiration | Created | Owner
1 | hskey-auth-cu578ZmFJ-IQ-*** | false | false | true | 2026-06-06 18:47:14 | 2026-06-06 17:47:14 | insomnia
2 | hskey-auth-QEoZ6zBIuYFe-*** | false | false | true | 2026-06-06 19:55:30 | 2026-06-06 18:55:30 | insomnia
3 | hskey-auth--b04FYyZRdTE-*** | false | false | true | 2026-06-06 20:00:40 | 2026-06-06 19:00:40 | insomniaПодробнее этот способ рассмотрим в следующем разделе.
Второй способ - регистрация со стороны клиента. В клиенте при подключении ищем опцию “Add Account Using Alternate Server”.
Клиент редиректнет на ваш домен и покажет одноразовый key ноды:
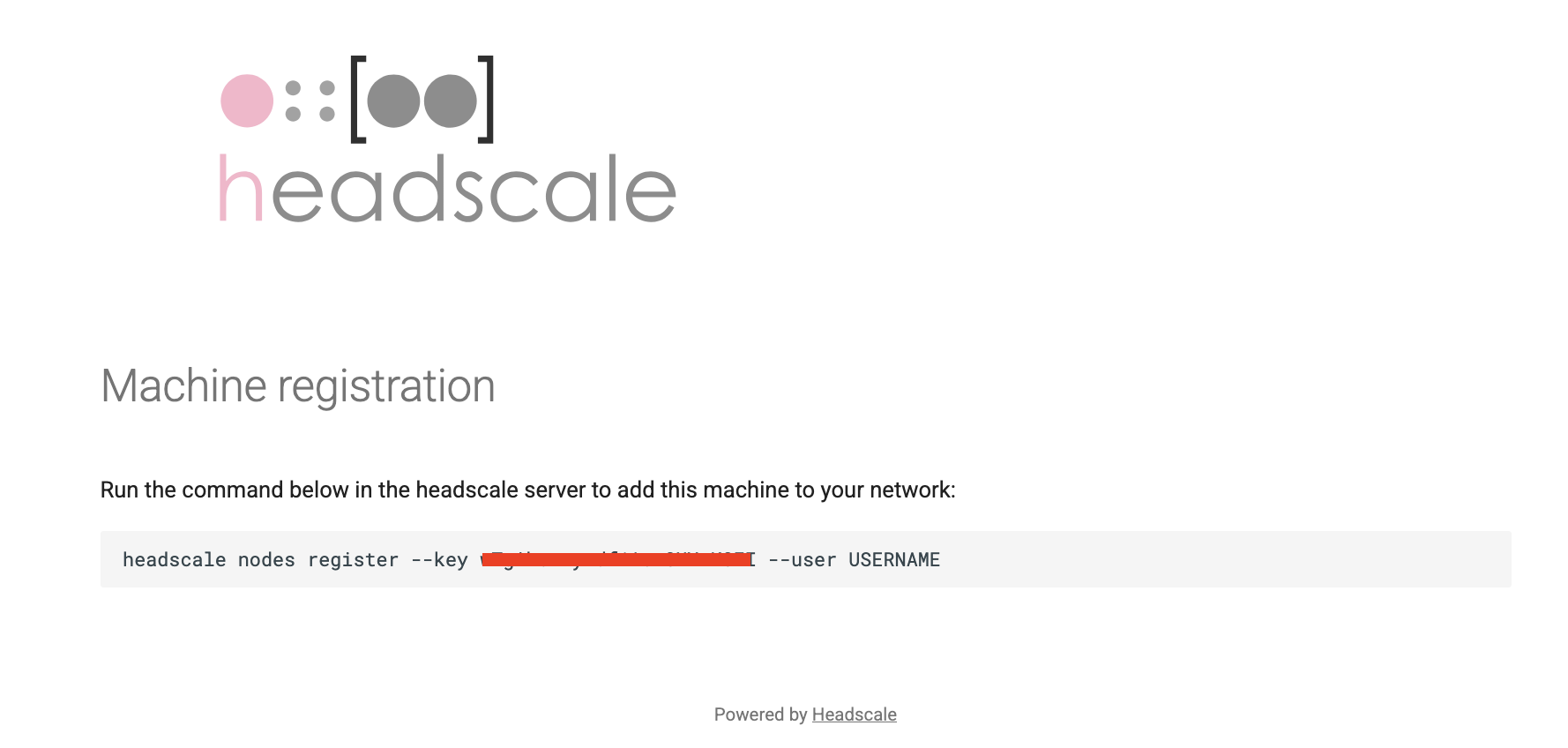
На сервере регистрируем ноду с этим key и именем юзера (из headscale users list):
docker exec headscale headscale nodes register --key <KEY> --user insomniaВажно: <KEY> - это публичный ключ ноды из браузерного экрана, не preauth-token. Это разные сущности: preauth-token нода предъявляет координатору сама (--auth-key=...), а key координатор использует, чтобы зарегистрировать ноду, которую клиент уже показал.
После регистрации docker exec headscale headscale nodes list покажет ноду с tailnet-IP. Ниже переименуем ее Name и Hostname.
Переименование пользователя и ноды
Если нужно переименовать юзера:
docker exec headscale headscale users rename --identifier <UID> --new-name <new>После rename в headscale nodes list колонка User может еще какое-то время показывать старое имя - это кеш. Можно подождать или перезапустить сервис:
docker compose -f ~/services/headscale/docker-compose.yml restart headscaleЕсли посмотрите headscale nodes list, name и hostname вам, скорее всего, не понравятся.
Hostname- это системное имя машины. То, что клиент прислал при регистрации. Изменяется только со стороны клиента. Может быть рандомным видаinvalid-amextwbf, если headscale не смог распарсить заглавные символы, пробелы, точки, спецсимволы. На примере macOS-клиента меняется так:sudo tailscale set --hostname=mac. На андроиде это Device name.Name- то, что использует MagicDNS (<name>.<base_domain>). Меняется на сервере:headscale nodes rename --identifier <NODE_ID> <new_name>.
7. Минимальный тест работоспособности - регистрация одной ноды
Цель шага - убедиться, что координатор принимает ноды и выдает им IP. Если шаг проходит, значит DNS, Caddy и проброс портов настроены корректно.
Берем Tailscale-клиент с https://tailscale.com/download. Дальше на примере macOS:
sudo tailscale up \
--login-server=https://headscale.insomnia.cat \
--auth-key=<PREAUTH_KEY>Флаг --auth-key заменяет интерактивный браузерный логин из предыдущего раздела.
Проверка:
# на клиенте
tailscale status
# на VPS
docker exec headscale headscale nodes listВ обоих местах должна быть нода с tailnet-IP вида 100.64.x.x. Если нода видна с обеих сторон - значит, координатор живой и доступен извне.
Если нужно откатить ноду:
# на клиенте - выходим и снимаем демона
sudo tailscale logout
sudo tailscale down
# на VPS - удаляем ноду из headscale
docker exec headscale headscale nodes list # смотрим ID ноды
docker exec headscale headscale nodes delete --identifier <NODE_ID> --force8. Нативные метрики headscale в Prometheus
Разделы 8 и 9 будут полезны, только если вам нужен мониторинг. На работу сервисов они не влияют.
В разделе 3 подключили контейнер headscale к docker-сети observability_default. Теперь в ~/services/observability/prometheus/prometheus.yml добавляем job с именем контейнера в качестве target (резолвится встроенным docker-DNS внутри той же сети):
- job_name: 'headscale'
static_configs:
- targets: ['headscale:9090']headscale - имя контейнера (container_name из docker-compose), 9090 - порт внутри контейнера, не хостовой. Docker DNS внутри сети резолвит имя в IP контейнера в этой сети. Трафик идет через docker-bridge observability_default.
Перечитываем конфиг Prometheus без рестарта:
docker compose -f ~/services/observability/docker-compose.yml exec prometheus kill -HUP 1Ждем ~15-30 секунд (обычно сразу) и проверяем, что таргет поднялся:
curl -s http://localhost:9090/api/v1/targets \
| jq '.data.activeTargets[] | select(.labels.job == "headscale") | {scrapeUrl, health, lastError}'Ожидаем:
{
"scrapeUrl": "http://headscale:9090/metrics",
"health": "up",
"lastError": ""
}Дашборд под нативные метрики
Готового публичного дашборда под нативные метрики headscale на grafana.com я не нашел. Набросал свой: https://gist.github.com/nilptrr/883509da7aaae83dc70094a0315ffd63
Эти метрики включают HTTP-запросы, RPS по кодам, HTTP latency, другие headscale-специфичные метрики (не разбирался, добавил на будущее).
Имена и описания метрик
nodestore_*собраны блоком в верхней части файла, в полях Name и Help - читаются без знания Go: https://github.com/juanfont/headscale/blob/main/hscontrol/state/node_store.go
Импорт в Grafana:
Dashboards -> New -> Import dashboard.Upload dashboard JSON file-> выбрать скачанный файл.- На странице импорта выбрать datasource - Prometheus.
- Открыть, проверить, что графики рисуются.
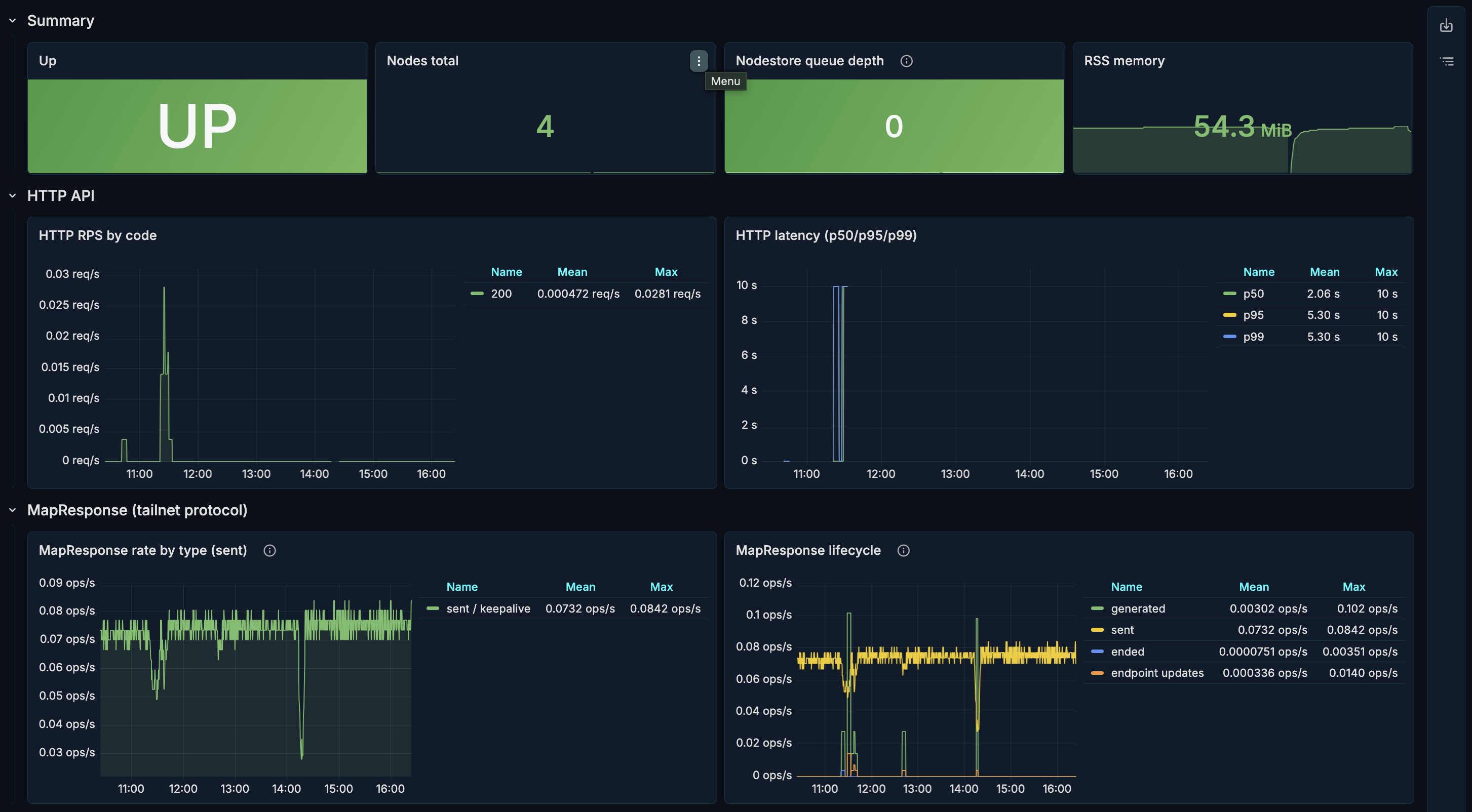
Дальше мы добавим уже существующий дашборд Headscale Overview, но он больше про нод, юзеров, ключи. А этот - про здоровье самого сервиса headscale.
9. Метрики нод через tailscale-exporter
Берем adinhodovic/tailscale-exporter. Под него есть дашборд Headscale Overview (импортируем его в следующих разделах).
Работает это так:
- headscale внутри
observability_defaultотдает gRPC-API на порту 50443 (для этого в разделе 2 мы выставилиgrpc_listen_addr: 0.0.0.0:50443). tailscale-exporterходит по этому gRPC, конвертирует ответы в Prometheus-метрики (headscale_users_info,headscale_nodes_online,headscale_preauthkeys_info, …) и отдает их на:9250/metrics.- Prometheus скрейпит экспортер из той же сети по имени контейнера.
9.1. Включить gRPC в headscale без TLS
В разделе 2 в ~/services/headscale/config/config.yaml мы задали grpc_allow_insecure: true. У headscale TLS-настройка одна на оба порта (HTTP API на 8080 + gRPC на 50443) - если ее включить, сломается Caddy на проксировании 8080: он ожидает HTTP, а получит TLS-handshake. Мы включаем grpc_allow_insecure, и это безопасно, потому что трафик не покидает хост.
Убедитесь, что у вас действительно grpc_listen_addr: 0.0.0.0:50443, а не 127.0.0.1, потому что иначе headscale будет слушать только loopback своего контейнера, и экспортер до него не достучится.
9.2. API-ключ для exporter
Создаем API-ключ для аутентификации экспортера. Я задал большой срок жизни, читатель пусть решает сам:
docker exec headscale headscale apikeys create --expiration 36500dСохраните ключ, потому что потом посмотреть его целиком не получится.
9.3. Ключ в .env-файл рядом с compose
Чтобы не хранить API-ключ в docker-compose.yml в открытом виде, кладем его в .env, оставляем чтение/запись только владельцу:
touch ~/services/headscale/.env
chmod 600 ~/services/headscale/.env
nano ~/services/headscale/.envВ файл пишем одну строку - имя переменной из compose и сам ключ:
HEADSCALE_API_KEY=<ключ из 9.2>Если каталог сервиса версионируется в git (как в части 2), добавьте .env в .gitignore до первого коммита, иначе ключ уедет в репозиторий:
echo ".env" >> ~/services/headscale/.gitignore9.4. Сервис в docker-compose.yml
В ~/services/headscale/docker-compose.yml рядом с сервисом headscale добавляем второй сервис:
tailscale-exporter:
image: adinhodovic/tailscale-exporter:0.6.0
container_name: tailscale-exporter
restart: unless-stopped
mem_limit: 64m
environment:
HEADSCALE_ADDRESS: "headscale:50443"
HEADSCALE_API_KEY: "${HEADSCALE_API_KEY}"
HEADSCALE_INSECURE: "true"
networks:
- default
- observabilityРазбор:
- Версия
0.6.0зафиксирована явно, неlatest. - В
HEADSCALE_ADDRESSиспользуем внутреннее имя контейнераheadscale:50443. Оно резолвится docker DNS внутри сетиobservability_default. HEADSCALE_INSECURE: "true"- потому что задалиgrpc_allow_insecure: true, и экспортер не должен проверять SSL.- Подключен к двум сетям:
defaultдля самой compose-связки,observabilityдля общения с Prometheus.
9.5. Поднимаем headscale и exporter
cd ~/services/headscale
docker compose up -d --force-recreate headscale tailscale-exporter
# headscale должен сообщить, что gRPC слушает на 0.0.0.0
docker compose logs --tail 50 headscale | grep -iE "grpc|listening"
# а exporter - что подключился и собрал данные
docker compose logs --tail 50 tailscale-exporterВ логах headscale ожидаем строки:
INF Enabling remote gRPC at 0.0.0.0:50443
WRN gRPC is running without security
INF listening and serving gRPC on: 0.0.0.0:50443WRN gRPC is running without security - из-за grpc_allow_insecure: true, это норма.
9.6. Job в Prometheus
В ~/services/observability/prometheus/prometheus.yml добавляем второй headscale job. Используемый нами дашборд требует лейблы cluster/namespace, поэтому добавляем их.
- job_name: 'tailscale-exporter'
static_configs:
- targets: ['tailscale-exporter:9250']
labels:
cluster: 'vps'
namespace: 'headscale'vps и headscale - произвольные строки, важно только, чтобы они были непустыми. После применения они появятся в меню сверху.
Перечитываем конфиг Prometheus:
docker compose -f ~/services/observability/docker-compose.yml exec prometheus kill -HUP 1Проверяем, что target ожил:
curl -s http://localhost:9090/api/v1/targets \
| jq '.data.activeTargets[] | select(.labels.job == "tailscale-exporter") | {scrapeUrl, health}'Проверяем, что экспортер получает эти метрики:
curl -s 'http://localhost:9090/api/v1/query?query=headscale_scrape_collector_success' \
| jq '.data.result[] | {collector: .metric.collector, value: .value[1]}'Будет что-то вроде:
{
"collector": "apikeys",
"value": "1"
}
{
"collector": "health",
"value": "1"
}
{
"collector": "nodes",
"value": "1"
}
{
"collector": "preauthkeys",
"value": "1"
}
{
"collector": "users",
"value": "1"
}Если все value = 0, экспортер не может достучаться до headscale по gRPC. Проверяем grpc_listen_addr: 0.0.0.0:50443 (не 127.0.0.1) и обязательно пересоздаем оба контейнера через --force-recreate.
9.7. Импорт дашборда
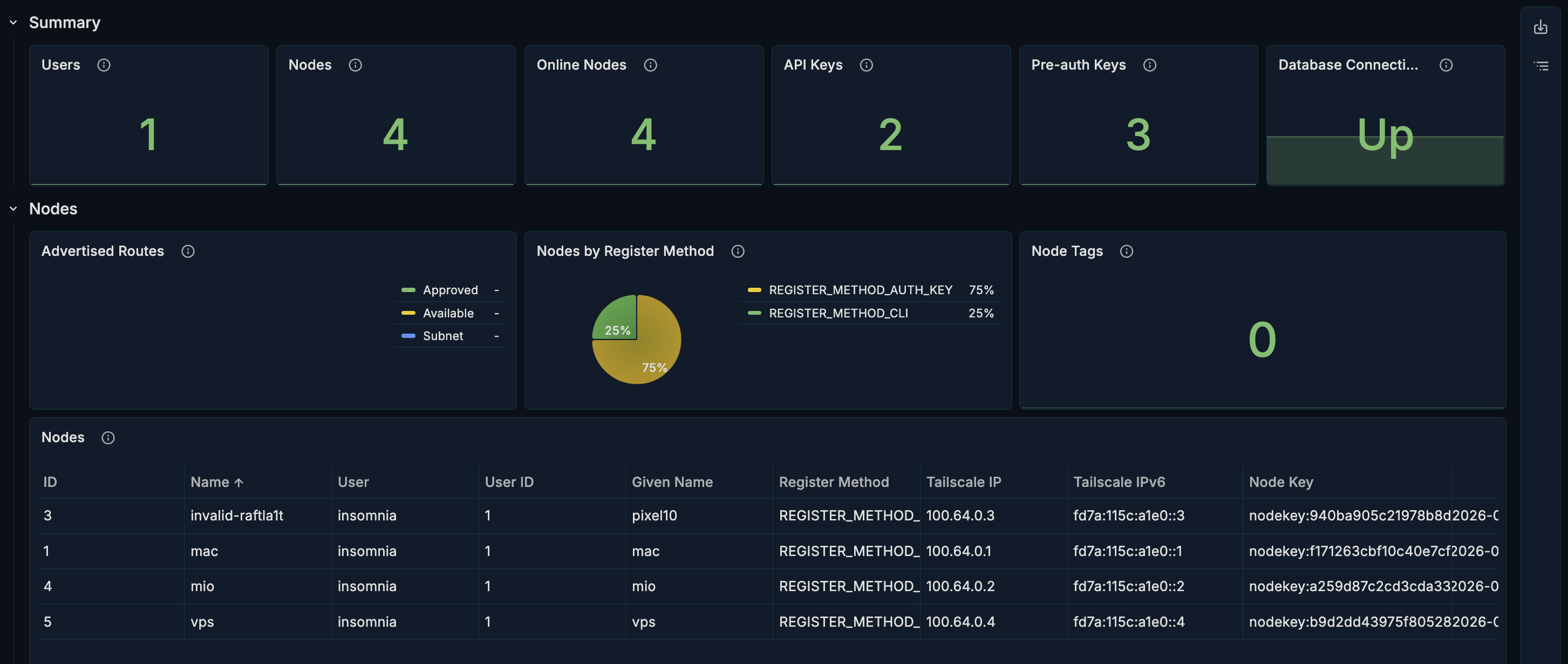
В Grafana: Dashboards -> New -> Import dashboard, в поле Paste a Grafana.com dashboard URL or ID вводим ID 24516 (Headscale Overview, ссылка на него: https://grafana.com/grafana/dashboards/24516-headscale-overview/).
Выбираем Prometheus-datasource. После импорта в выпадающих меню сверху выбираем:
cluster -> vpsnamespace -> headscalejob -> tailscale-exporter
Графики должны рисоваться.
10. Подключение домашнего сервера к tailnet
В разделе 7 был тест с временной нодой. Теперь подключаем домашний сервер к tailnet постоянно - чтобы дальше Prometheus с VPS мог скрейпить с него метрики через приватный канал, а с мака можно было ходить на сервисы по mio.insomnia.internal.
Установка Tailscale на домашнем сервере (Debian 13)
Скрипт из официального репозитория - сам определит дистрибутив, подключит репо и поставит клиент через apt:
curl -fsSL https://tailscale.com/install.sh | shПосле установки запускаем системный демон:
sudo systemctl enable --now tailscaledБез enable --now после reboot домашний сервер отвалится от tailnet.
Регистрация ноды на координаторе
На VPS выпускаем одноразовый preauth-key:
docker exec headscale headscale preauthkeys create \
--user 1 --expiration 1h--user 1 - тот же ID, что в разделе 6 (см. headscale users list).
Копируем ключ из вывода и выполняем на домашнем сервере:
sudo tailscale up \
--login-server=https://headscale.insomnia.cat \
--auth-key=<PREAUTH_KEY выше> \
--hostname=miohostname задаем явно, чтобы не получить запись вида invalid-strkrb71.
Проверка регистрации
На домашнем сервере смотрим, какой tailnet-IP назначил координатор:
tailscale statusЕсли тестовую ноду из раздела 7 вы удалили, в tailnet сейчас только домашний сервер, и ходить ему не к кому (поднимем ноду VPS в следующем разделе).
Со стороны координатора на VPS:
docker exec headscale headscale nodes listУвидите строку со своим hostname, статусом online и IP вида 100.64.0.x.
11. Tailscale-клиент на самом VPS
Напоминаю, что headscale - только координатор, в самой mesh-сети его нет. Теперь на VPS добавляем ноду именно на уровне data-plane.
Как и выше, я решил поставить tailscale-клиент нативно прямо на хост, без контейнера. Docker-образ потребовал бы дополнительной настройки (проброс /dev/net/tun, NET_ADMIN, volume под state), которая для ноды-хоста нецелесообразна.
curl -fsSL https://tailscale.com/install.sh | sh
sudo systemctl enable --now tailscaledВыпускаем preauth-ключ под VPS-ноду:
docker exec headscale headscale preauthkeys create --user 1 --expiration 1hИ регистрируем VPS:
sudo tailscale up \
--login-server=https://headscale.insomnia.cat \
--auth-key=<PREAUTH_KEY> \
--hostname=vpsПроверяем с обеих сторон, что mesh реально собрался:
# на VPS
tailscale status # должны быть подключенные ноды
tailscale ip -4 # IP VPS в tailnet, например 100.64.0.3
ping -c3 mio # пингуем домашний сервер по hostname, подставьте свой
# на домашнем сервере
tailscale status # аналогично выводу выше
ping -c3 vps # пинг в обратную сторону
# на VPS, через координатор
docker exec headscale headscale nodes list # обе ноды будут online12. Метрики домашнего сервера через tailnet (node_exporter + cAdvisor)
Как и разделы 8-9, этот шаг опциональный.
На домашнем сервере ставим node_exporter и cAdvisor в Docker. Те же образы, что у нас уже стоят на VPS в observability-стеке.
12.1. node_exporter на домашнем сервере
Prometheus и Grafana продолжают крутиться только на VPS - на домашнем сервере поднимаем только экспортеры. Оба (node_exporter и cAdvisor дальше) будут жить в одном compose-проекте ~/services/exporters/.
На домашнем сервере:
mkdir -p ~/services/exporters
cd ~/services/exporters~/services/exporters/docker-compose.yml (пока с одним сервисом, второй дальше) - конфиг сервиса из части 2, дополненный маунтами /proc, /sys, / и флагами --path.*:
services:
node_exporter:
image: prom/node-exporter:latest
container_name: node_exporter
restart: unless-stopped
pid: host
network_mode: host
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.sysfs=/host/sys'
- '--path.rootfs=/rootfs'
- '--collector.filesystem.mount-points-exclude=^/(sys|proc|dev|host|etc)($$|/)'
mem_limit: 64mnetwork_mode: hostозначает, что контейнер слушает прямо на сетевых интерфейсах хоста, в том числе наtailscale0. Так Prometheus с VPS сможет достучаться до экспортера по tailnet-IP домашнего сервера (или по MagicDNS-имениmio.insomnia.internal).
Поднимаем:
docker compose up -d
docker compose ps
ss -tlnp | grep 9100 # должно слушаться на *:9100
curl -s http://localhost:9100/metrics | head -3 # go_gc_duration_seconds{quantile="0"} не 012.2. Firewall
На домашнем сервере экспортеры (node_exporter и cAdvisor дальше) слушают на всех интерфейсах, включая локальную сеть, поэтому UFW не обязателен. Включаем, только если нет доверия к устройствам в локальной сети.
Tailnet полностью открываем, из локальной сети пускаем только SSH:
sudo ufw default deny incoming # дефолт UFW, на всякий случай явно
sudo ufw default allow outgoing
sudo ufw allow in on tailscale0 # весь tailnet-трафик разрешен
sudo ufw allow from 192.168.0.0/24 to any port 22 proto tcp # SSH из локалки (подставьте свою подсеть)
sudo ufw enable
sudo ufw status verbose12.3. Добавить target в Prometheus на VPS
Это то, ради чего настраивался Headscale. Все команды ниже - на VPS.
К домашнему серверу будем обращаться по MagicDNS-имени (mio.insomnia.internal), а не по tailnet-IP. Имя стабильнее - не сломается при переподключении или повторной регистрации ноды.
Зону insomnia.internal (base_domain из раздела 2) обслуживает локальный tailscale-клиент через MagicDNS. Сначала убедимся, что Prometheus из своего контейнера может туда достучаться:
docker exec prometheus wget -qO- http://mio.insomnia.internal:9100/metrics | head -3Если в ответе пришли метрики (go_gc_duration_seconds{quantile="0"} 2.3452e-05) - резолв работает.
Дополняем job node в ~/services/observability/prometheus/prometheus.yml, источники разделяем через лейбл instance:
- job_name: 'node'
static_configs:
- targets: ['host.docker.internal:9100']
labels:
instance: 'vps'
- targets: ['mio.insomnia.internal:9100']
labels:
instance: 'mio'host.docker.internal:9100- target VPS, как в части 2. У Prometheus в compose-файле стоитextra_hosts: ["host.docker.internal:host-gateway"]- имя резолвится в текущий шлюз docker-сети, не ломается, если Docker переедет на другую подсеть.mio.insomnia.internal:9100- домашний сервер через tailnet. MagicDNS отрезолвит в текущий tailnet-IP.instance: 'mio'- произвольная метка. Без лейбла Prometheus подставит адрес, и по графикам будет непонятно, какой хост.
Теперь в job
nodeдва хоста. Если в части 4 вы заводили алерт на загрузку CPU, оберните внутреннийavgв формуле вavg by (instance)(...)(как описано в части 4) - иначе CPU обеих машин усреднится в одно значение, и алерт перестанет ловить нагрузку на отдельной машине.
Маршрутизация: Prometheus в контейнере -> bridge сети observability_default (br-<id>) -> хост VPS -> интерфейс tailscale0 (создавали, когда ставили клиент) -> tailnet-туннель -> домашний сервер.
Перечитываем конфиг Prometheus:
docker compose -f ~/services/observability/docker-compose.yml exec prometheus kill -HUP 1Проверяем, что оба target’а живы:
curl -s http://localhost:9090/api/v1/targets \
| jq '.data.activeTargets[] | select(.labels.job == "node") | {instance: .labels.instance, scrapeUrl, health, lastError}'Должно быть:
{
"instance": "mio",
"scrapeUrl": "http://mio.insomnia.internal:9100/metrics",
"health": "up",
"lastError": ""
}
{
"instance": "vps",
"scrapeUrl": "http://host.docker.internal:9100/metrics",
"health": "up",
"lastError": ""
}Дашборд Node Exporter Full из предыдущих частей сам подхватит ноду в меню instance.
12.4. cAdvisor на домашнем сервере
На домашнем сервере тоже крутится Docker. Собираем метрики контейнеров через cAdvisor по tailnet тем же путем.
Директория уже есть (~/services/exporters/), добавляем второй сервис в тот же docker-compose.yml, рядом с node_exporter:
cadvisor:
image: gcr.io/cadvisor/cadvisor:latest
container_name: cadvisor
restart: unless-stopped
network_mode: host
privileged: true
devices:
- /dev/kmsg
volumes:
- /:/rootfs:ro
- /var/run:/var/run:ro
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
- /dev/disk/:/dev/disk:ro
mem_limit: 256mКонфиг почти идентичен тому, что на VPS (часть 2). На VPS cAdvisor запущен в bridge с ports: "127.0.0.1:8080:8080", потому что Prometheus стучится к нему изнутри той же compose-сети по имени контейнера. На домашнем сервере Prometheus приходит снаружи через tailscale0, поэтому cAdvisor должен слушать на этом интерфейсе - используем network_mode: host.
Поднимаем:
cd ~/services/exporters
docker compose up -d
docker compose ps # должны быть оба контейнера в running
ss -tlnp | grep 8080
curl -s http://localhost:8080/metrics | head -3Дополняем job cadvisor на VPS:
- job_name: 'cadvisor'
static_configs:
- targets: ['cadvisor:8080']
labels:
instance: 'vps'
- targets: ['mio.insomnia.internal:8080']
labels:
instance: 'mio'Перечитываем конфиг Prometheus:
docker compose -f ~/services/observability/docker-compose.yml exec prometheus kill -HUP 1Проверка обоих таргетов (если unknown, можно подождать ~15 секунд и повторить):
curl -s http://localhost:9090/api/v1/targets \
| jq '.data.activeTargets[] | select(.labels.job == "cadvisor") | {instance: .labels.instance, scrapeUrl, health, lastError}'Оба должны быть “health”: “up”. Дашборд cAdvisor подхватит таргет.
13. Минимальные алерты на headscale
Базовая алерт-инфраструктура уже настроена в части 4 - здесь только два новых правила.
13.1. Координатор недоступен
- Name:
Headscale coordinator down - Query (Prometheus, expression A):
up{job="headscale"} - Alert condition:
WHEN QUERY IS BELOW 1 - Folder:
vps - Labels:
severity: critical - Evaluation group:
vps-1m - Pending period:
2m - Keep firing for:
None - Alert state if no data or all values are null:
Alerting - Contact point:
Telegram VPS - Summary:
Headscale coordinator is down - Description:
Coordinator unreachable for 2+ min. Existing tunnels keep working via cached peer info, new registrations blocked. Check: docker compose -f ~/services/headscale/docker-compose.yml ps
13.2. Экспортер не достучался до headscale
- Name:
tailscale-exporter not collecting - Query (Prometheus, expression A):
min(headscale_scrape_collector_success) - Alert condition:
WHEN QUERY IS BELOW 1 - Folder:
vps - Labels:
severity: warning - Evaluation group:
vps-1m - Pending period:
5m - Keep firing for:
None - Alert state if no data or all values are null:
Normal - Contact point:
Telegram VPS - Summary:
tailscale-exporter is not collecting data from headscale - Description:
One or more collectors returned 0. gRPC broken, API key expired, or headscale not recreated after config change. Tailnet still works, but Headscale Overview dashboard is empty. Check: docker logs tailscale-exporter --tail 50
severity не critical, потому что data plane продолжает работать, страдает только мониторинг.
Проверка
На VPS остановить координатор:
docker compose -f ~/services/headscale/docker-compose.yml stop headscaleЧерез ~3 минуты в Telegram прилетит Headscale coordinator down.
Поднимаем обратно (docker compose -f ~/services/headscale/docker-compose.yml start headscale) - через минуту станет Resolved.
Что дальше
Большую часть того, что хотел, я описал в этой серии постов. Возможно, еще будут статьи по VictoriaLogs, деплою конфигов через Ansible и ротации секретов, но основная часть закончена. Теперь есть инфраструктура, на которой можно разворачивать любые свои сервисы и мониторить их.