Содержание:
- Создание Telegram-бота через BotFather
- Contact point и notification policy
- Базовые алерты: Memory, Disk, CPU, Container down, Swap
- Метрики Caddy per host
- Алерты на Caddy: 5xx и p99 latency
- BetterStack для мониторинга самой Grafana
- Проверка работы алерта
В первой статье мы сделали базовую настройку алертов со стороны провайдера DO. Они остаются - даже если Grafana упадет, они продолжат работать. Но эти алерты максимально простые и не позволяют настраивать специфичные условия и выбирать канал для отправки алерта.
В части 2 мы настроили метрики системы и сервисов, в части 3 - метрики HTTP-трафика. В этой статье добавим алерты в телеграм, если что-то идет не так.
Финальный чеклист
Telegram и contact point
- Бот создан через @BotFather, токен в KeePassXC
-
chat_idизвестен (через @userinfobot или @RawDataBot) -
Контакт-поинт
Telegram VPSв Grafana создан, тест прошел -
Default notification policy указывает на
Telegram VPS
Базовые алерты
- Memory > 90% / 5m
- Disk > 85% / 10m
- CPU > 95% / 15m
- Container down / 2m
- Swap > 50% / 5m (опционально)
Caddy
-
Caddyfile: глобальный блок
metrics { per_host } - 5xx rate > 5 запросов / 5m
- p99 latency > 1s / 10m (блог, фильтр по host)
Внешний мониторинг
-
BetterStack настроен на
https://grafana.insomnia.cat
Проверка
- Один из алертов реально отправил сообщение в Telegram
Главное
- Алертинг через Grafana. У нас задача настроить личный VPS, поэтому нам достаточно Grafana Alerts, и более мощные инструменты, вроде AlertManager, не рассматриваем (память едят, а потребности в них нет).
- Избегаем ложных и лишних срабатываний. Короткие пики - это нормальная ситуация. Поэтому алерты будем настраивать мягко. Смысл мониторинга в том, чтобы предпринимать действия. Если алерт будет срабатывать постоянно и нести чисто информативную функцию о разовых скачках нагрузки, то начнет игнорироваться, и тогда можно пропустить реальную проблему.
- Внешний источник мониторинга. Grafana будет на VPS. Если упадет Grafana, мы не узнаем о проблемах на VPS. Если упадет VPS, мы не узнаем о проблемах на других хостах. Поэтому в виде страховки будет внешний сервис BetterStack.
1. Создаем Telegram-бота
В Telegram-чате с @BotFather -> /newbot, создаем бота. Сохраняем токен. В своем боте нажимаем Start - боты не умеют писать, пока общение не инициировано юзером.
Узнаем chat_id - например, через @userinfobot. Он нужен, чтобы Grafana знала, куда слать сообщения.
2. Contact point в Grafana
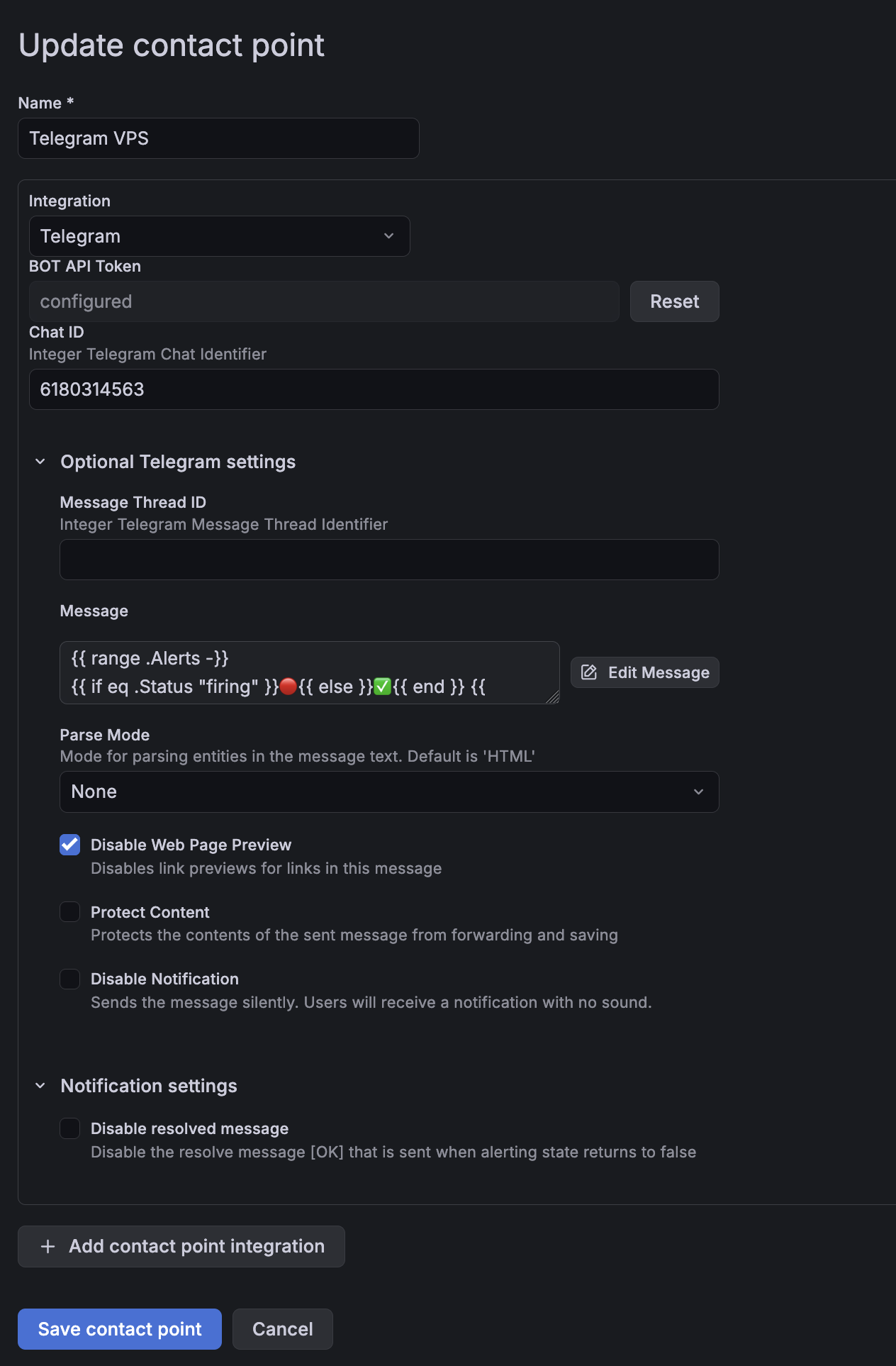
В Grafana: Alerting -> Notification configuration -> New contact point:
- Name:
Telegram VPS - Integration: Telegram
- Bot API Token: токен от BotFather
- Chat ID: наш
chat_id - Optional Telegram settings -> Message -> Edit message -> Enter custom message. Можно оставить дефолтный, но свой удобнее. Сообщения используют Go-шаблоны:
{{ range .Alerts -}}
{{ if eq .Status "firing" }}🔴{{ else }}✅{{ end }} {{ .Labels.alertname }}
{{ if eq .Labels.severity "critical" }}🚨{{ else }}⚠️{{ end }} {{ .Labels.severity }}
{{ .Annotations.summary }}
{{ .Annotations.description }}
{{- end }}Шаблон рисует алерты вида:
🔴 Disk almost full
⚠️ warning
Disk usage above 85%
Disk: 87.3%. Clean up: docker system prune -af, old logs, unused volumes.
---
✅ Disk almost full
⚠️ warning
Disk usage above 85%
Disk: 84.1%. Clean up: docker system prune -af, old logs, unused volumes.{{ range .Alerts -}}- итерация в цикле по массиву .Alerts.-в конце - не переносить строку шаблона.{{ if eq .Status "firing" }}🔴{{ else }}✅{{ end }} {{ .Labels.alertname }}- если статус текущего алерта (.Status) firing, рисуем красный кружок, иначе зеленую галочку, в конце строки название алерта (например, Disk almost full).{{ if eq .Labels.severity "critical" }}🚨{{ else }}⚠️{{ end }} {{ .Labels.severity }}- аналогичная логика, но с severity (срочностью).{{ .Annotations.summary }}- краткое сообщение алерта.{{ .Annotations.description }}- детальное сообщение алерта.{{- end }}- конец цикла без переноса строки.
Также в Optional Telegram settings нужно поправить два пункта:
- Parse Mode: выбрать
None. По умолчанию Grafana шлет сообщение как HTML, и если в сообщении алерта окажутся символы, встречающиеся в HTML-тегах (>, <, &), то Telegram не сможет распарсить сообщение. Поэтому отключаем парсинг. Если все-таки нужна разметка в алертах, то лучше выбрать MarkdownV2, но его также нужно будет экранировать. В рамках статьи не рассматривается. - Disable Web Page Preview: поставить галочку. Если в Description окажется ссылка (например, на дашборд), Telegram попытается ее добавить превью под сообщением. В алерте оно не нужно - визуальный мусор плюс лишний запрос на наш URL.
Дальше Save contact point и Test. В Telegram должно прийти тестовое сообщение. Оно пока будет без контекста, сейчас важен только факт отправки:
🔴 TestAlert
⚠️
Notification test3. Notification policy
Alerting -> Notification policies -> Default policy -> Edit.
Здесь есть опции, связанные с группами. Группа - это похожие алерты, объединенные каким-то лейблом. Все алерты группы шлются одним сообщением.
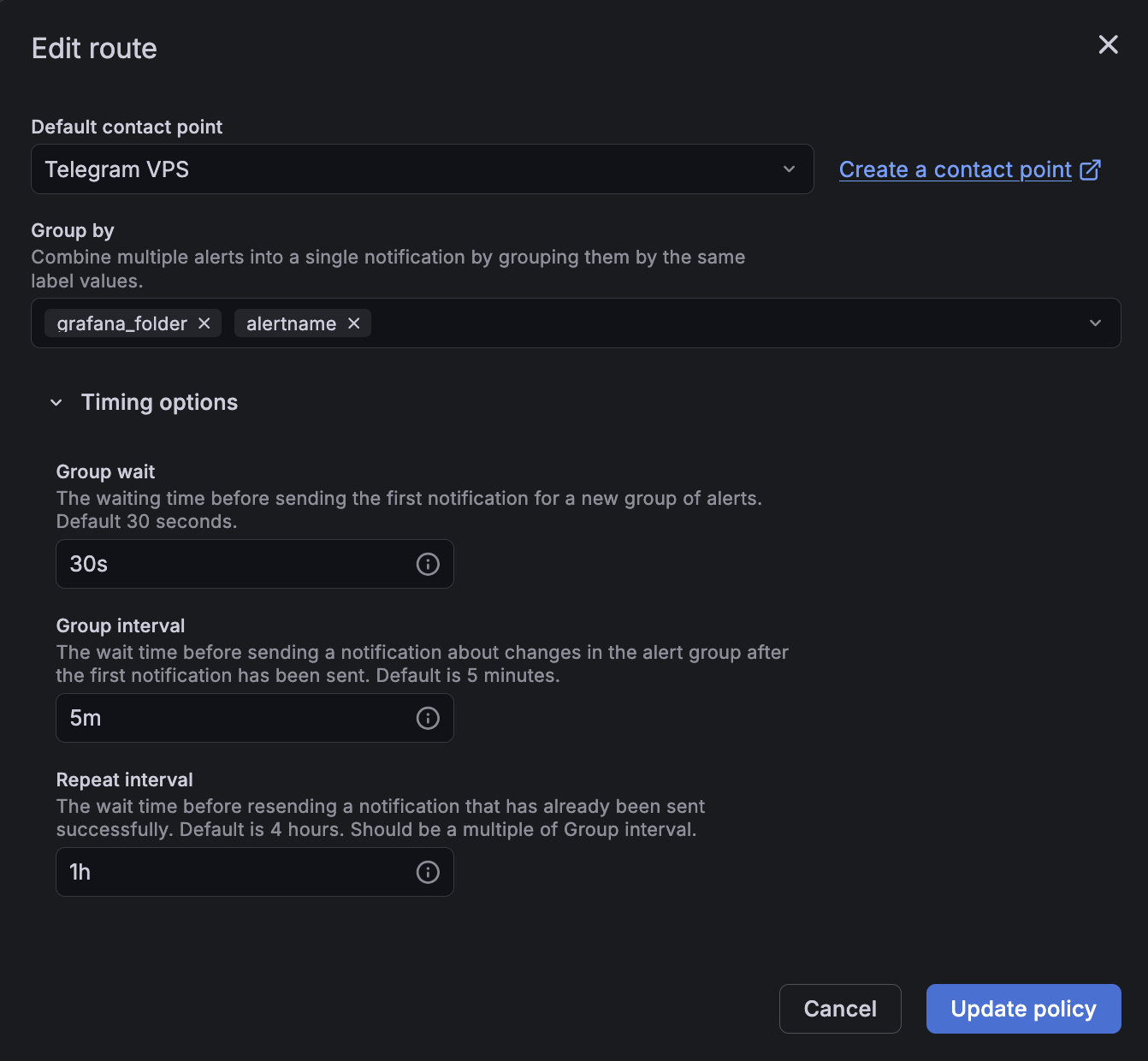
Поля, которые нужно настроить:
- Default contact point: ->
Telegram VPS. - Group by - я оставил дефолт,
grafana_folder,alertname. Два алерта попадают в одну группу, только если у них совпали оба значения лейбловgrafana_folderиalertname. - Group wait: Сколько ждать перед отправкой после срабатывания первого алерта - вдруг в эту же группу придут еще алерты, чтобы объединить их в одно сообщение. Я оставил дефолт - 30s.
- Например, сработал алерт на рост потребления CPU. Grafana ждет 30 секунд - вдруг в это окно сработают еще какие-то алерты. Тогда они отправятся пачкой.
- Group interval: Как часто слать обновления по уже открытой группе, если в нее добавились новые алерты. Этот параметр работает внутри одной группы, то есть при группировке по папке и названию алерта алерт на CPU и алерт на память - это разные группы, а значит не попадут под условие. Смысл этого параметра в том, чтобы сгладить шторм из алертов. Оставил дефолт, 5m.
- Например, сработал и отправился алерт на Container down (name=prometheus). Через минуту сработал Container down (name=grafana). Он попадает в ту же группу, потому что совпадают оба лейбла из Group by. Через 5 минут после первой отправки летит обновление этой же группы с новым алертом, итого в новой отправке будет 2 алерта - по prometheus и grafana.
- Repeat interval: Как часто повторять уведомление, пока алерт остается в
Firing. Я поставил1hкак компромисс между “не орать, пока чиню” и “не забыть, если отвлекся”. Советую не ставить15mи меньше. Если проблема продолжается, то это спам, который можно начать игнорировать.
Сохраняем - Update policy.
Alerting -> Silence нужен для мьюта алертов. Что-то алертит - идем мьюить, чиним, потом убираем (или снимется само через duration).
4. Базовые алерты
Alerting -> Alert rules -> New alert rule. Форма создания правила разделена на шесть блоков.
Сначала опишем, потом посмотрим на конкретных алертах. Но сперва - небольшое отступление про метрики, на которых строятся запросы.
Типы метрик Prometheus
Основных видов 3:
- Counter - метрика, которая только увеличивается. Перезапуск отслеживаемого сервиса может обнулить метрику. Пример: общее количество обработанных HTTP-запросов или суммарное количество отправленных байт.
- Gauge - метрика, которая может увеличиваться или уменьшаться. Пример: потребление ресурсов CPU.
- Histogram - распределение значений метрики по бакетам (группам) + сумма значений метрики и количество записей этой метрики. Через гистограммы удобно смотреть перцентили. Под капотом - те же счетчики Counter. Это составная метрика. Пример:
caddy_http_request_duration_seconds_bucket{le="1.0"}-> количество http-запросов, продолжительность которых <= 1 секунде. Сама по себе имеет тип Counter, как и перечисленные ниже.caddy_http_request_duration_seconds_bucket{le="0.3"}-> количество http-запросов, продолжительность которых <= 300 миллисекунд.caddy_http_request_duration_seconds_sum-> суммарное количество секунд на обработку http-запросов.caddy_http_request_duration_seconds_count-> суммарное количество http-запросов.
- Также есть Summary - хранит заранее посчитанные на стороне сервиса квантили (например, p50/p95/p99) + sum + count. В статье не используем.
Структура алерта
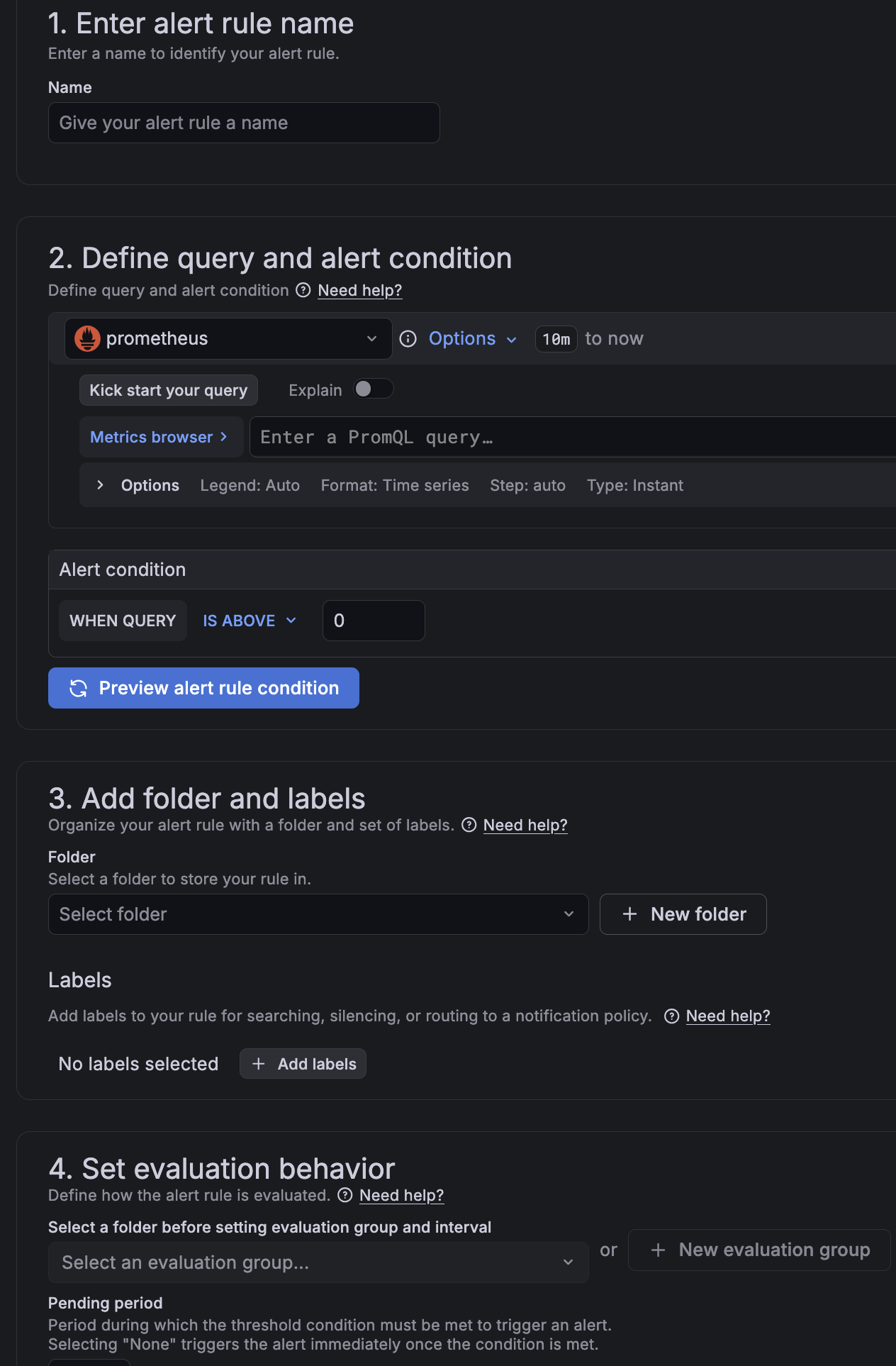
1. Enter alert rule name. По нему правило ищется в списке и подставляется в сообщение как лейбл alertname. Брать короткое и описательное, вроде Memory high, Container down и т.д.
2. Define query and alert condition. Условие срабатывания алерта:
- Datasource:
prometheus(пока единственный, добавленный во второй части). - Time range:
10m to now. Окно, для которого Grafana вызывает запрос к метрике, т.е. от текущего момента до момента 10 минут назад. Оставляем дефолт. Выше я упоминал, что основных видов метрик 3:- для метрик типа Gauge этот диапазон не важен совсем - запрос будет брать последнюю точку метрики (логично, что мы мониторим актуальное состояние CPU, например).
- метрики типа Counter и составленные из Counter гистограммы часто используются в связке с функциями
rate()/increase()(средняя скорость роста метрики за временное окно и на сколько метрика выросла за окно соответственно). Например, на сколько выросло количество запросов продолжительностью меньше секунды относительно значения 5 минут назад:increase(caddy_http_request_duration_seconds_bucket{le="1.0"}[5m]), скорость роста этой же метрики относительно значения тех же 5 минут назад:rate(caddy_http_request_duration_seconds_bucket{le="1.0"}[5m]). - Окно
[5m]внутриrate()/increase()- это внутренний интервал самой функции: он задает, на сколько назад от момента вычисления смотреть, и не зависит от time range запроса. Следить нужно за другим - чтобы интервал скрейпа был достаточно частым и в окно попадало хотя бы две точки метрики, иначеrate()нечего считать. При scrape interval 15s окна[5m]хватает с запасом.
- Поле PromQL (правее, режим Code). Сюда вставляем выражение.
- Run queries - выполняет запрос и показывает результат.
- Alert condition - threshold. Сравнивает значение запроса с константой. Дает проверить условие алерта.
3. Add folder and labels.
- Folder - папка хранения правил, просто для их организации.
- Labels - метки самого правила. По ним работает роутинг в Notification policies и silence-фильтры. Я буду использовать
severity: warning/severity: critical.
4. Set evaluation behavior.
- Evaluation group - группа правил с общим интервалом проверки. Создаем
vps-1m(interval1m), складываем туда все правила. Один интервал на все правила - проще не путаться. Правила этой группы будут проверяться каждую минуту. - Pending period - сколько должно держаться условие, прежде чем правило перейдет в
Firing. Ставим:5mдля RAM - не алертим на точечные пики RAM,15m- от пиков CPU.Noneозначает “сработать сразу”, лучше не использовать. - Keep firing for - сколько правило продолжает считаться
Firingпосле того, как условие уже не выполняется. Я оставилNone. - Configure no data and error handling - что делать, если запрос не вернул данных или упал с ошибкой.
- Alert state if no data or all values are null: по дефолту ставлю
Alerting- пропажа метрики обычно означает, что что-то сломалось (упал экспортер и т.д). - Alert state if execution error or timeout: ставлю для всех
Normal- если запрос упал с ошибкой, считаем все нормальным. Разовые таймауты PromQL не должны генерить ложные алерты.
- Alert state if no data or all values are null: по дефолту ставлю
5. Configure notifications.
- Contact point:
Telegram VPS, который создан в разделе 2.
6. Configure notification message.
- Summary, Description - попадают в шаблон Telegram-сообщения.
Сохраняем, идем в Alert rules - алерт будет со статусом Normal или Firing.
Полный пример моих алертов:
4.1 Memory > 90% / 5m
- Name:
Memory high - Query (Prometheus, expression A):
100 * (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)) - Alert condition:
WHEN QUERY IS ABOVE 90 - Folder:
vps - Labels:
severity: warning - Evaluation group:
vps-1m - Pending period:
5m - Keep firing for:
None - Contact point:
Telegram VPS - Summary:
RAM usage above 90% - Description:
Memory: {{ printf "%.1f" $values.A.Value }}%. Check what's eating memory.
4.2 Disk > 85% / 10m
- Name:
Disk almost full - Query (Prometheus, expression A):
100 * (1 - (node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"})) - Alert condition:
WHEN QUERY IS ABOVE 85 - Folder:
vps - Labels:
severity: warning - Evaluation group:
vps-1m - Pending period:
10m - Keep firing for:
None - Contact point:
Telegram VPS - Summary:
Disk usage above 85% - Description:
Disk: {{ printf "%.1f" $values.A.Value }}%. Clean up: docker system prune -af, old logs, unused volumes.
4.3 CPU > 95% / 15m
- Name:
CPU high - Query (Prometheus, expression A):
100 - (avg(rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) - Alert condition:
WHEN QUERY IS ABOVE 95 - Folder:
vps - Labels:
severity: warning - Evaluation group:
vps-1m - Pending period:
15m - Keep firing for:
None - Contact point:
Telegram VPS - Summary:
CPU above 95% for 15 minutes - Description:
CPU: {{ printf "%.1f" $values.A.Value }}%. Short spikes (docker build, cron) are normal - this has been high for 15+ minutes.
Pending period: 15m - потому что короткие пики (docker build, пересборка блога, тяжелая cron-задача) - норма. Подозрительно только когда CPU держится выше 95% четверть часа.
Формула усредняет загрузку по всем CPU одного хоста. Сейчас Prometheus скрейпит только VPS, так что этого достаточно. Когда добавится второй хост (домашний сервер, см. конец статьи), оберни внутреннюю часть в avg by (instance)(...) - иначе CPU обеих машин сольется в одно среднее, и алерт потеряет смысл.
4.4 Container down
- Name:
Container down - Query (Prometheus, expression A):
min by (name) (time() - container_last_seen{name=~".+"}) - Alert condition:
WHEN QUERY IS ABOVE 60 - Folder:
vps - Labels:
severity: critical - Evaluation group:
vps-1m - Pending period:
2m - Keep firing for:
None - Alert state if no data or all values are null:
Normal - Contact point:
Telegram VPS - Summary:
Container {{ $labels.name }} is down - Description:
Container {{ $labels.name }} has not been seen for {{ printf "%.0f" $values.A.Value }}s. Check with: docker ps -a
container_last_seen - метрика cAdvisor: когда контейнер последний раз был живой. time() - container_last_seen дает, сколько секунд назад его видели, а threshold IS ABOVE 60 ловит момент, когда cAdvisor перестал видеть контейнер.
Ставим Alert state if no data на Normal, потому что cAdvisor может временно не отдать метрики - запрос вернет пусто, и при дефолтном Alerting алерт ложно ушел бы в Firing. С Normal молчим, если данных нет.
4.5 Swap > 50% / 5m (опционально)
- Name:
Swap high - Query (Prometheus, expression A):
100 * (1 - (node_memory_SwapFree_bytes / node_memory_SwapTotal_bytes)) - Alert condition:
WHEN QUERY IS ABOVE 50 - Folder:
vps - Labels:
severity: warning - Evaluation group:
vps-1m - Pending period:
5m - Keep firing for:
None - Contact point:
Telegram VPS - Summary:
Swap usage above 50% - Description:
Swap: {{ printf "%.1f" $values.A.Value }}%. RAM is exhausted - check memory-hungry processes.
Если своп выделяется - значит RAM кончилась. Если памяти на сервере мало, может быть полезно знать.
5. Метрики Caddy per host
Дока Caddy по настройке метрик: https://caddyserver.com/docs/metrics
По умолчанию Caddy не добавляет лейбл host в Prometheus-метрики. Без него insomnia.cat и grafana.insomnia.cat попадают в одну кучу, и алерт на latency срабатывает из-за Grafana, а не из-за реальной проблемы с блогом.
Фикс - блок metrics на верхнем уровне глобального блока /etc/caddy/Caddyfile:
{
email your@email.com
metrics {
per_host
}
}Если в конфиге есть servers { metrics } - нужно его убрать, т.к. глобальный metrics заменяет его полностью. Без этого конфиг будет невалидный.
Валидируем и перезапускаем:
sudo caddy validate --config /etc/caddy/Caddyfile
sudo systemctl restart caddyИменно restart, не reload. reload делает перезагрузку конфига, но не сбрасывает метрики (как я выяснил на практике). Старые метрики без лейбла host продолжают жить, и фильтр по хосту не находит ничего. После полного рестарта метрики начинают собираться заново с per_host.
После применения в метриках появится лейбл host, и запросы можно фильтровать: {host="insomnia.cat"} - только блог, {host="grafana.insomnia.cat"} - только Grafana.
6. Алерты на Caddy
Эти алерты работают только если выполнен гайд из части 3 - метрики Caddy должны быть в Prometheus.
6.1 5xx rate > 5 запросов / 5m
- Name:
Caddy 5xx - Query (Prometheus, expression A):
sum(increase(caddy_http_request_duration_seconds_count{code=~"5.."}[5m])) or vector(0) - Alert condition:
WHEN QUERY IS ABOVE 5 - Folder:
vps - Labels:
severity: warning - Evaluation group:
vps-1m - Pending period:
5m - Keep firing for:
None - Contact point:
Telegram VPS - Summary:
Caddy returns 5xx - Description:
{{ printf "%.0f" $values.A.Value }} 5xx responses in the last 5 minutes. Check logs and upstream services.
Caddy экспортирует гистограмму caddy_http_request_duration_seconds. Счетчик с суффиксом _count считает запросы с теми же лейблами (включая code), поэтому используем его.
or vector(0) - заглушка, нужна потому, что Caddy не создает лейблы для кодов, которых еще не было. Если пятисотых ответов не было ни разу - метрики с code=~"5.." нет в TSDB, sum() возвращает пусто, Grafana будет ложно алертить. С or vector(0) запрос всегда возвращает число: 0 когда чисто, реальный счетчик когда нет.
Пороги алерта зависят от профиля нагрузки конкретного сервиса - подбирайте под свой трафик.
6.2 p99 latency > 1s / 10m
- Name:
Caddy p99 high - Query (Prometheus, expression A):
histogram_quantile(0.99, sum by (le) (rate(caddy_http_request_duration_seconds_bucket{host="insomnia.cat"}[5m])) ) - Alert condition:
WHEN QUERY IS ABOVE 1 - Folder:
vps - Labels:
severity: warning - Evaluation group:
vps-1m - Pending period:
10m - Keep firing for:
None - Contact point:
Telegram VPS - Summary:
Caddy p99 latency above 1s - Description:
p99 latency: {{ printf "%.3f" $values.A.Value }}s. Check disk I/O and Caddy logs.
Фильтр {host="insomnia.cat"} изолирует блог от Grafana. Статика должна укладываться быстро, поэтому я поставил условием > 1s.
7. BetterStack для мониторинга самой Grafana
Если Grafana или весь VPS упадет - мы не получим алерт. Поэтому нам нужен мониторинг для мониторинга.
Я использую бесплатный BetterStack, но есть и другие - StatusCake, Uptime Kuma и т.д. Регаемся на https://betterstack.com, выбираем Uptime monitoring -> Grafana -> URL.
Переходим в созданный монитор -> Alert us when -> URL returns HTTP status other than -> 401 -> Save changes. Алерт будет идти письмом на почту.
Если монитор будет получать 401, то Grafana можно считать живой.
8. Тестим алерты
Проще всего временно занизить порог одного из реальных алертов и подождать.
Memory сейчас (на свежей VPS под нагрузкой Prometheus + Grafana + cadvisor) обычно держится в районе 60-80%. Меняем threshold алерта 4.1 с 90 на 50, ждем 5-7 минут (Pending period: 5m). В Telegram должно прилететь сообщение. После теста возвращаем порог обратно.
Альтернатива для проверки Container down - поднять одноразовый контейнер, дать cAdvisor его заметить, затем остановить:
docker run -d --name testnginx nginx
# подождать ~минуту, чтобы cAdvisor увидел контейнер
docker stop testnginxЧерез 2-3 минуты должен прийти Container down (name=testnginx). После теста - docker rm testnginx.
Сам cadvisor для этого теста останавливать нельзя: он источник метрики container_last_seen. Если убить cadvisor, Prometheus пометит его серии stale, запрос уйдет в no-data, а для Container down у нас стоит Alert state if no data = Normal (раздел 4.4) - алерт промолчит, а не сработает. По той же причине не трогаем prometheus (хранилище метрик) и grafana (движок алертинга).
Что еще можно добавить
Сейчас алерты покрывают только верхнеуровневые характеристики (память, CPU, диск, контейнеры, Caddy).
Кандидаты на алерты: node_exporter (хост)
-
Load average,
node_load5. -
Network errors.
rate(node_network_receive_errs_total[5m]) > 0. -
Disk IO latency.
rate(node_disk_io_time_seconds_total[5m]) > 0.7 / 10m. -
File descriptors.
node_filefd_allocated / node_filefd_maximum > 0.8 / 10m. Утечка дескрипторов в каком-то сервисе. -
NTP / time drift.
abs(node_timex_offset_seconds) > 0.5. Расхождение часов может ломать сертификаты и логи.
cadvisor (контейнеры)
-
OOM-kill контейнера.
increase(container_oom_events_total[5m]) > 0. -
Контейнер близок к
mem_limit.container_memory_usage_bytes / container_spec_memory_limit_bytes > 0.9 / 5m. Дает среагировать до ООМ-киллера.
fail2ban
Для него нужен отдельный экспортер, например https://github.com/hctrdev/fail2ban-prometheus-exporter. (Может, добавлю в одной из будущих статей)
Алерты:
-
Резкий рост banned.
rate(f2b_jail_banned_total[10m]) > 1 / 10m- больше одного бана за 10 минут может говорить о ддосе. -
Падение fail2ban.
up{job="fail2ban"} == 0 for 5m.
headscale (нативные метрики)
В одной из будущих статей будет headscale, так что на будущее.
-
Координатор недоступен.
up{job="headscale"} == 0 for 2m. Аналог “Container down” для конкретного сервиса. Критичный. -
HTTP error rate у самого headscale.
sum(rate(headscale_http_requests_total{code=~"5.."}[5m])) > 0.1. Если координатор начал отдавать 5xx своим клиентам.
tailscale-exporter (бизнес-метрики headscale)
-
Exporter не может скрейпить headscale.
headscale_scrape_collector_success == 0 for 5m. Сам exporter жив (up{job="tailscale-exporter"} == 1), но соединение с headscale упало. -
Preauth-key скоро истечет.
headscale_preauthkeys_expiration_timestamp - time() < 7 * 24 * 3600- за неделю до окончания.
Домашний сервер (связь через tailnet)
После подключения к tailnet Prometheus на VPS будет скрейпить его по MagicDNS (http://mio.insomnia.internal:9100).
node_exporter поддерживает метрики здоровья батареи, что может быть ценным для домашнего сервера на старом ноуте. Помимо основных node_exporter метрик, можно взять следующие две:
- Износ батареи.
- Низкий заряд батареи. Актуально если сервер не постоянно на зарядке.
Что дальше
Скорее всего, в следующей статье будет настройка домашнего сервера и headscale для связи. VPS в таком случае начнет выступать просто как прокси, вся реальная работа сервисов может происходить на домашнем сервере.