Содержание:
- Включаем metrics в Caddy
- UFW-правило для доступа из docker-сети
- Добавляем Caddy в
prometheus.yml - Импорт дашборда
В первой части подняли хост и базовую безопасность, во второй - Caddy как реверс-прокси, Prometheus + Grafana c дашбордами по хосту и контейнерам. Снаружи видим, что блог работает, изнутри есть метрики хоста и контейнеров. Но мы не видим сам HTTP-трафик: сколько запросов в секунду, какой процент ответов с ошибкой сервера (5xx) и т.д. В конце поста получим настроенный дашборд для HTTP-метрик, который можно редактировать под свои нужды.
Чеклист
-
В
/etc/caddy/Caddyfileглобальный блок:admin off+servers { metrics { per_host } } -
В
/etc/caddy/Caddyfileдобавлен блок:2019 { metrics /metrics } -
caddy validateпроходит -
UFW-правило
from 172.16.0.0/12 to any port 2019 proto tcp -
curl -s http://localhost:2019/metrics | grep caddy_ | headвозвращает строкиcaddy_* -
В
prometheus.ymlдобавлен jobcaddy - Prometheus перечитал конфиг (SIGHUP)
-
Таргет
caddyв Prometheus в состоянииup - Импортирован дашборд Caddy
Главное
- По умолчанию Caddy не собирает HTTP-метрики - сбор включается глобальной директивой
servers { metrics { per_host } }(per_hostдобавляет разбивку по доменам через меткуhost). После этого метрики доступны на admin endpoint,localhost:2019/metrics. - Admin endpoint слушает только на
localhost, а Prometheus стучится из контейнера через docker-сеть и туда не дотянется. Поэтому admin отключаем (admin off) и поднимаем свой блок:2019 { metrics /metrics }на всех интерфейсах. Цена: сadmin offперестает работатьcaddy reload(он ходит в admin API), конфиг применяется черезsystemctl restart caddy. - Наружу не открываем: порт 2019 пускает только трафик из docker-сетей (
172.16.0.0/12), снаружи UFW его блокирует.
1. Включаем metrics в Caddy
Дока Caddy по метрикам: https://caddyserver.com/docs/metrics
Включим метрики в /etc/caddy/Caddyfile:
{
email username@example.com
admin off
servers {
metrics {
per_host
}
}
}
:2019 {
metrics /metrics
}
# ниже - остальные блоки из части 2 (example.com, grafana.example.com и т.д.)admin offотключает admin API и освобождает порт 2019 под наш блокservers { metrics { per_host } }включает экспорт HTTP-метрик серверов (семействоcaddy_http_*) с разбивкой по доменам (меткаhost):2019 { metrics /metrics }- свой блок на порту 2019 (на всех интерфейсах), отдает метрики по пути/metrics
Валидируем и перечитываем:
sudo caddy validate --config /etc/caddy/Caddyfile
sudo systemctl reload caddyС admin off дальнейшие правки конфига Caddy применяются через sudo systemctl restart caddy: caddy reload управляет Caddy по admin API, а его больше нет.
Если в логах будет Caddyfile input is not formatted; run 'caddy fmt --overwrite' to fix inconsistencies {"adapter": "caddyfile", "file": "/etc/caddy/Caddyfile", "line": 39}:
sudo caddy fmt --overwrite /etc/caddy/CaddyfileПроверим, что метрики доступны на хосте:
curl -s http://localhost:2019/metrics | grep caddy_ | headДолжны быть строки вроде caddy_http_requests_total, caddy_http_request_duration_seconds_bucket и т.д. (семейство caddy_http_* появляется после первых запросов к сайту).
2. UFW-правило для доступа из docker-сети
Напоминаю, что Prometheus живет в контейнере и стучится к Caddy через docker-bridge (виртуальный мост между контейнером и хостом). По умолчанию UFW блокирует трафик от docker-сетей к хосту.
Так же, как это делали для node_exporter в части 2, открываем 2019 для стандартного диапазона 172.16.0.0/12:
sudo ufw allow from 172.16.0.0/12 to any port 2019 proto tcp
sudo ufw reloadСнаружи 2019 по-прежнему недоступен: UFW пускает только source IP из 172.16.0.0/12.
3. Добавляем Caddy в prometheus.yml
В ~/services/observability/prometheus/prometheus.yml добавляем job:
- job_name: 'caddy'
static_configs:
- targets: ['172.17.0.1:2019']172.17.0.1 - дефолтный IP моста docker0. В части 2 node_exporter мы скрейпили по имени host.docker.internal:9100 (оно резолвится в этот же IP через extra_hosts у Prometheus) - здесь можно так же, host.docker.internal:2019: это надежнее хардкода, если docker0 переедет на другую подсеть.
Перечитываем конфиг Prometheus без рестарта:
docker compose -f ~/services/observability/docker-compose.yml exec prometheus kill -HUP 1Проверяем, что таргет ожил:
curl -s http://localhost:9090/api/v1/targets | jq '.data.activeTargets[] | select(.labels.job == "caddy") | {scrapeUrl, health}'Будет:
{
"scrapeUrl": "http://172.17.0.1:2019/metrics",
"health": "up"
}Если health: "down", проверьте UFW: sudo ufw status verbose. Должен отдать:
2019/tcp ALLOW IN 172.16.0.0/124. Импорт дашборда
Dashboards -> New -> Import.
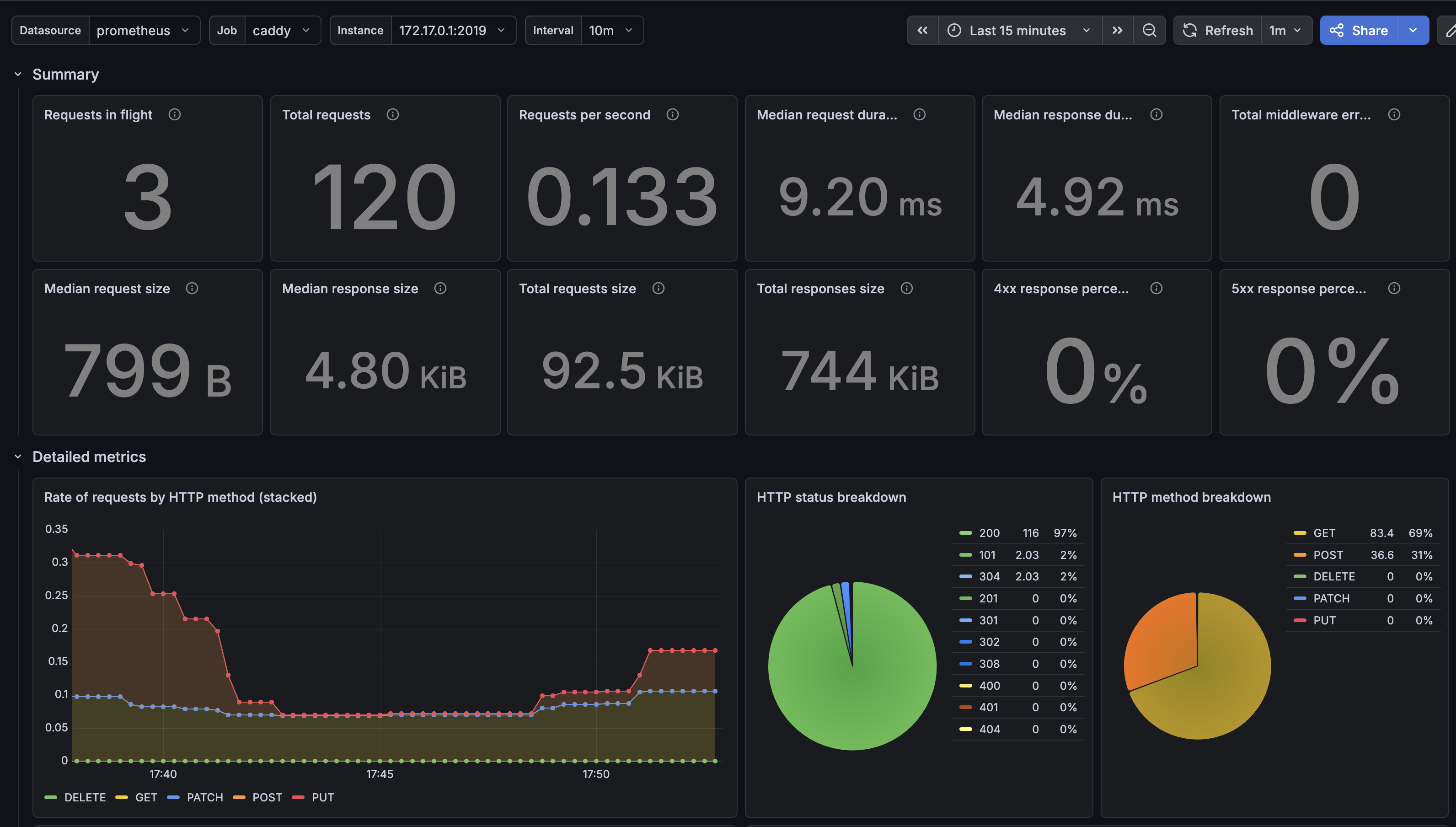
Я взял этот: https://grafana.com/grafana/dashboards/24146-caddy-hosts/, ID: 24146
На шаге импорта в поле datasource (DS_PROMETHEUS) выбираем Prometheus.
После импорта на дашборде увидим статистику по HTTP-запросам, разбивку по HTTP-кодам и т.д.
Дашборд называется Caddy Hosts и строит разбивку по доменам через метку host - она появляется как раз благодаря per_host, который мы включили в разделе 1. По умолчанию Caddy пишет отдельные метрики только для доменов, заданных в Caddyfile, а все прочие Host-заголовки (боты, сканеры) сваливает в один лейбл _other.
Что дальше
Метрики собираются, дашборд показывает графики. Следующий шаг - настройка алертинга (часть 4): при превышении порогов получаем уведомления в Telegram.